Performance Testing Activities Part 2

Performance Testing Activities Part 2

Administrator
|
Please follow Part 1 before this
4 Performance Testing using SilkPerformerThree components of SilkPerformer used in performance testing are as following – • Workbench: SilkPerformer Workbench is used for – Recording of test script, Debugging test script, Customizing test script, Setting baseline, Defining the workload, Execute the test • TrueLog Explorer: SilkPerformer TrueLog Explorer is used for – In depth of trial run, Customizing session, Customizing user data (parameterization), Adding verifications, Analysis of TrueLog on Error • Performance Explorer: SilkPerformer Performance Explorer is used for – Real time monitoring of client and server side measurements, Customizing measurement monitors, Customizing test report 4.1 Performance Test CyclePerformance Test Cycle is delineated below – 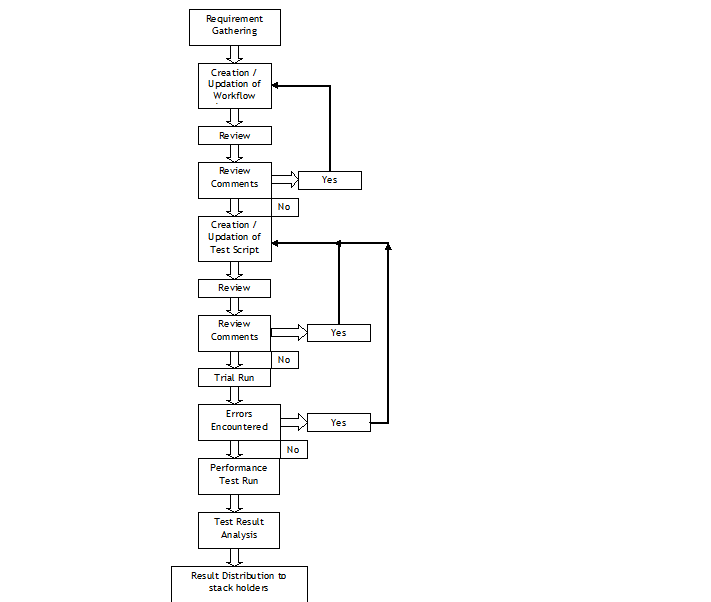 4.2 Performance Test StatisticsPerformance measurements which are gathered during test are as following – 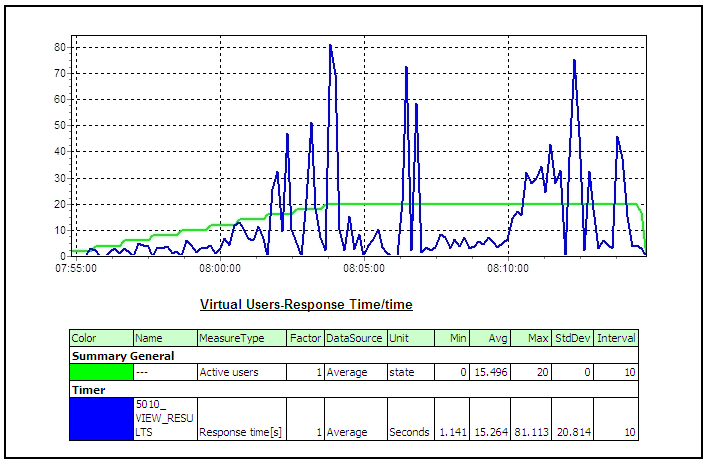 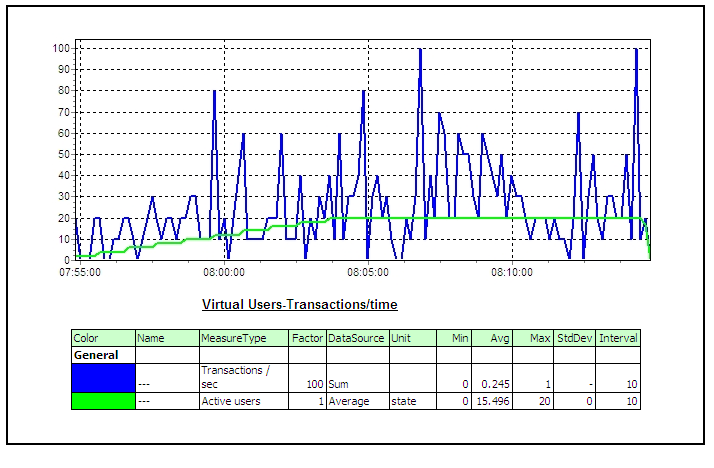 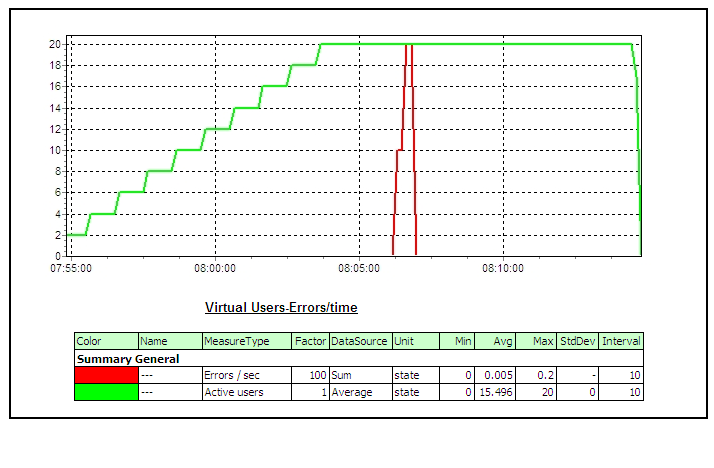 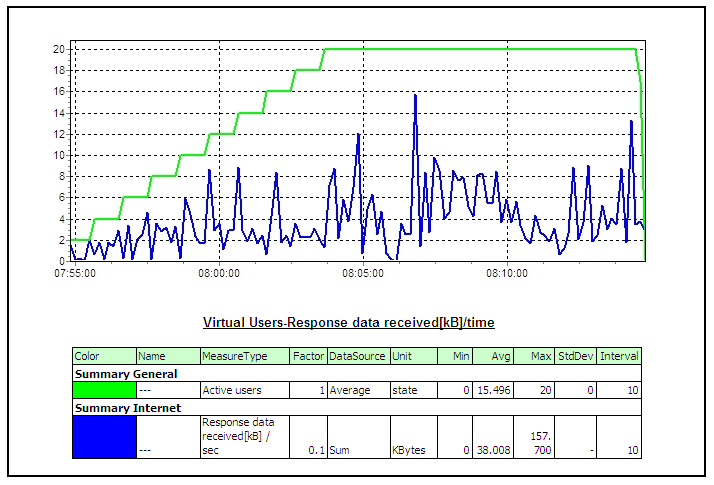 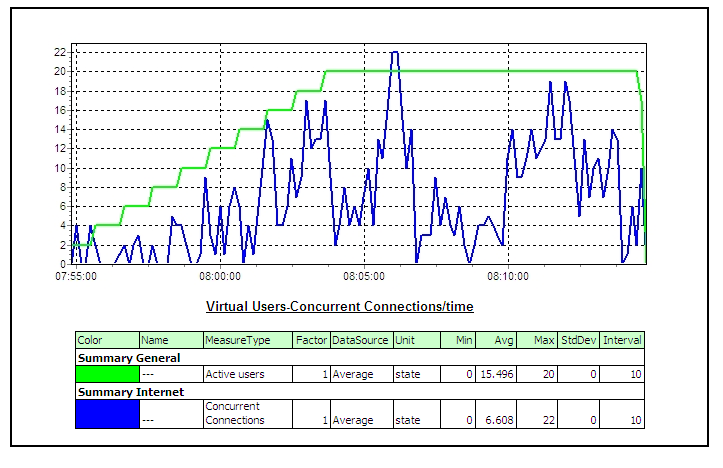 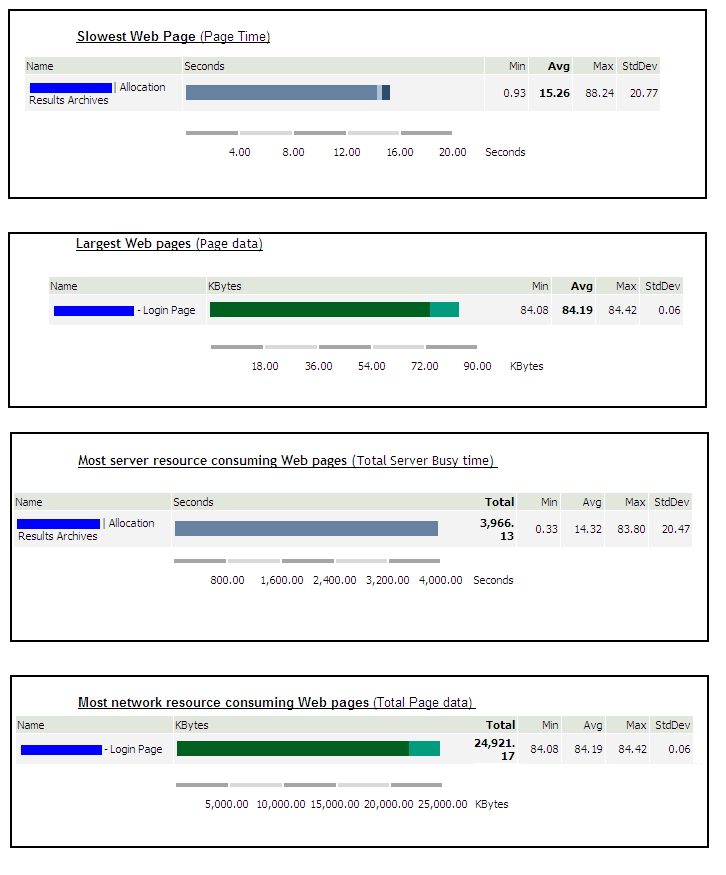 5 Common Pitfalls in Performance testingTest execution 4 days before deployment A better approach would be to execute and complete a performance, volume, load, soak or stress test 3-4 weeks before the actual deployment deadline or release date to migrate the application under test into its final destination the production environment. In addition time will be needed to review graphs and interpret results from the various performance-monitoring tools. Example of the additional tasks that may have to be performed the following are included: • Obtaining more unique data values from the subject matter experts to re-execute the tests with multiple iterations of data for processes that have unique data constraints, • Tuning the Database, • Rewriting programs with inefficient SQL statements, • Upgrading the LAN, • Upgrading the hardware, Missing trial runs (Proof of concept runs) A more pragmatic approach before jumping into a full-blown performance/volume/stress test is to conduct 2 trial runs for the automated scripts where the various support personnel are monitoring the system under test with a load that is first equal to 10% of the expected peak load in the production environment for the first trial run, and then with a load that is equal to 25% of the expected peak load in the production environment. With this proposed approach the various support personnel can first validate via proof of concept trial runs that they have the ability to monitor the various components of the system under test including the LAN, and second the test engineer can validate that the emulated end-users can playback the recorded business process. Lastly, with trial runs one can also validate that the application under test receives data from interface programs that run as batch scheduled jobs and generate traffic within the application. After the trial runs are successfully completed with a partial load of emulated end-users as described above then a decision can be made to initiate the execution of the performance/stress/volume test. Unnecessary risks in the live production environment Testing in a production environment can: crash the production environment, introduce false records, corrupt the production database, violate regulatory constraints, one may not be able to have the production environment a second time to repeat the test if needed. A project is better off re-creating an environment that closely mimics or parallels the production environment with the same number of servers, hardware, database size etc and using this production like environment to conduct the performance/stress/volume/load test. If the production-like environment is a virtual image of the production environment then the tester may have even obviated the need to extrapolate performance results from one environment to the other. Prevent Data Caching Populating and entering the same set of records into the application with the same automated scripts, when the performance/stress/load/volume tests were performed would cause data to be stored and buffered which does not fully exercise the database. The creation of automated test scripts with enough unique data records will prevent the data-caching problem from occurring. The test engineer who hands experience with the automation tool but lacks functional knowledge of the application under test should work with the subject matter experts and testers with functional knowledge of the application to identify enough sets of unique data records to repeat the performance/stress/volume/load test with distinct or unique values of data. For smaller applications the DBA may restore and refresh the database after each performance/stress/volume/load test to cleanse the database for values entered during a previous test run, in this way when the performance/load/volume/stress test is repeated with the same set of records the records will not be cached or buffered. Failure to notify system users, and disable users It must be notified in advance to all users via email or system messages when a performance/volume/stress/volume test will take place, what date, what time, and in which environment. As a second precautionary step disable all users log-on ids from the environment where the test will take place that are not associated with the test and only permit emulated end-users to log-on to the environment under test with the previously created dummy user ids (e.g. user001, user002, etc) and other users that are associated with the test for tasks such as performance monitoring of the test. Absence of a Contingency Plan The best test engineers can crash an application or bring down the LAN when conducting a stress test since stress testing is an inexact science. In reality many companies make educated guesses and assumptions about an application’s expected performance that may easily be proven false after the test takes place. The problem may take considerable time and one must have alternative plans or contingency plans for such an emergency. It is essential that test managers, test engineers, and support personnel not only document all potential risks but also mitigation actions to reduce the risks before starting a stress test. Not knowing what will be monitored Many a time teams get into a stress test without knowing what should be monitored during the stress test. Every project has applications with their own nuances, customizations, and idiosyncrasies that make them unique from other projects. While it would be very difficult to generate a generic list of all the components of an application that need to be monitored during a stress test it is fair to say that at the very minimum the following components should be monitored: the database, the project’s infrastructure (i.e. LAN), the servers, the application under test, etc. Team must have meetings with various managers, owners and stakeholders of the application under test and discuss all potential risks and areas that need to be monitored before conducting a stress test. Also create a point of contact list with names of the individuals, their phone numbers, and their tasks during the stress test after all the areas that will be monitored during the stress test have been identified. Every person associated with the stress test should have his/her role and responsibility clearly defined. Not extrapolating results If a stress/performance/volume tests were conducted in an environment that does not even come close to emulating the actual production environment then results would need to be extrapolated from one environment to the other. Many projects fail to do so and assume that if the application under test has an adequate response in one environment the same holds true for another environment without extrapolating results. There are many tools in the market from multiple vendors to help extrapolate results and if the test environment is a smaller scale of the production environment these third-party tools should be employed for extrapolating the test results.
~ seleniumtests.com
|
«
Return to Performance Testing
|
1 view|%1 views
| Free forum by Nabble | Edit this page |